
Background: sigmoid

“In response to the COVID-19 pandemic, the White House and a coalition of leading research groups have prepared the COVID-19 Open Research Dataset (CORD-19). CORD-19 is a resource of over 45,000 scholarly articles, including over 33,000 with full text, about COVID-19, SARS-CoV-2, and related coronaviruses. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.”
The data is available here:
Update on Sigmoid Fit Model
Updated today with data from 4/10/2020
We see that the model predicted 506.8708k total confirmed cases for the US for today (4/11/2020). As of 20:56 4/11/2020, the US has 532,879. That is around where my model predicts the value to be between the 12th and 13th of this month.
RNN Model
Basically it’s a neural network that has a feed-forward loop added that connects a hidden layer to itself existing as a hidden state.
Updated today with data from 4/10/2020
An RNN works with sequence data to make predictions using sequential memory.
The example they use in the link above involves asking a simple question like “What time is it?” First the word “What” enters the RNN to produce some output “01” but not before producing a “hidden state” The next input “time” produces an output “02” but it goes through a hidden state based on the one produced from the previous input combined with the one for this input. This continues sequentially all the way down to “?”, each word (input) incorporating the previous hidden state (which is a combination of the hidden states that came before it) to produce a final output.
This final output is passed into the feed-forward layer to classify an intent.
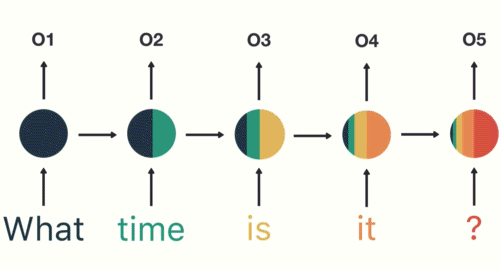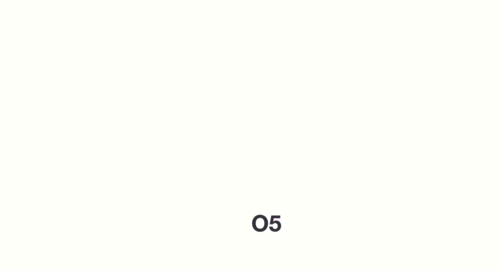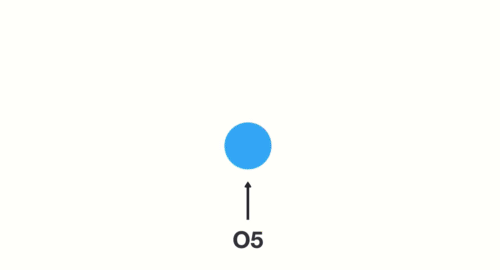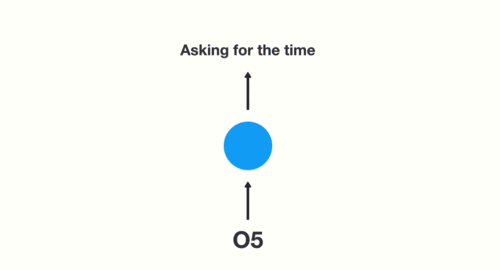
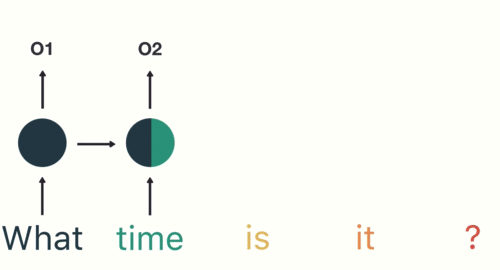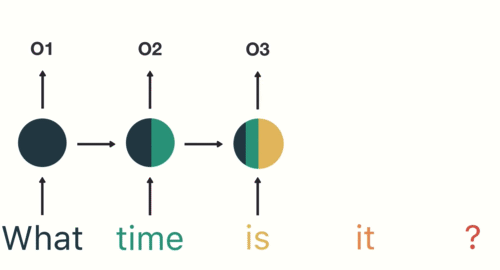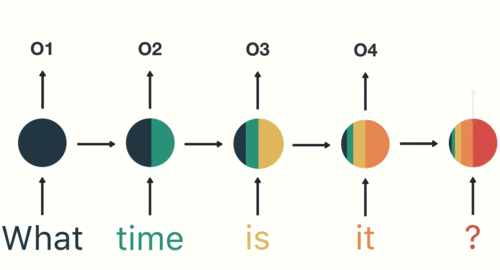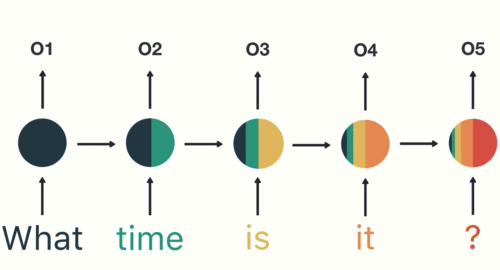
Here’s a closer look at the final hidden state of the example RNN:

As each successive step is processed, the RNN has trouble retaining information from the previous steps. In the above image, you can see the first two hidden states (from “What” and “time”, for instance) are cut into small slivers by the time it reaches the final step. This is known as the Vanishing Gradient problem.
Recall, that to train a neural network, there are three steps.
- A forward pass is done and a prediction is made
- This prediction is compared to the ground truth using a loss function. The loss function outputs an error value which is an estimate of how poorly the neural network is performing.
- Last, this error value is used to do back propagation, which calculates the gradients for each node in the neural network.
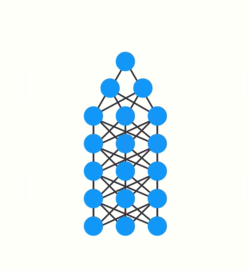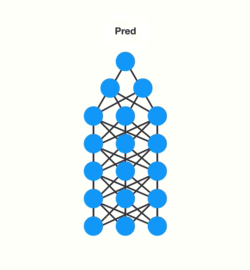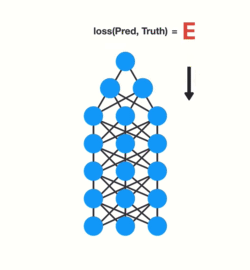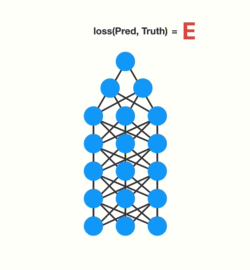
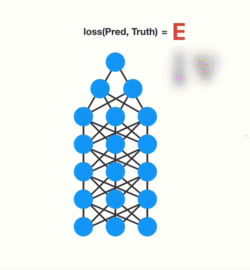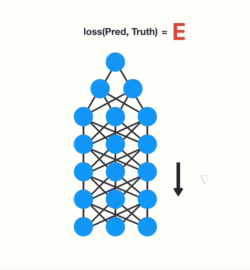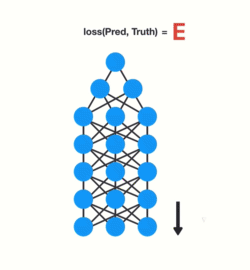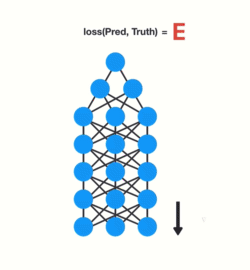
The ‘gradient’ is the value that’s used to adjust the neural network’s internal weights, enabling the network to learn. The bigger the gradient, the bigger the adjustments, and vice versa. Now, when we are dealing with multiple layers and back propagation, each node in a layer calculates its gradient with respect to the effects of gradients in the layer before it. So if the gradient in a layer is small, the gradient in the successive layer will be even smaller.
This means gradients exponentially shrink as it back propagates down. Earlier layers fail to do any learning as the internal weights are barely being adjusted due to such small gradients. This is the Vanishing Gradient problem.
In general, RNN’s have bad short term memory. To combat this, the Long Short-Term Memory (LSTM) is made. Or a Gated Recurrent Unit (GRU). These basically are RNN’s that can learn long-term dependencies using mechanisms called ‘gates’. These gates are just different tensor operations that can learn what information to add/remove to the hidden state.
I am not using an LSTM or GRU right now because an RNN trains faster and uses less computational resources.
test