
What is the difference between AI, Machine Learning, and Deep Learning?
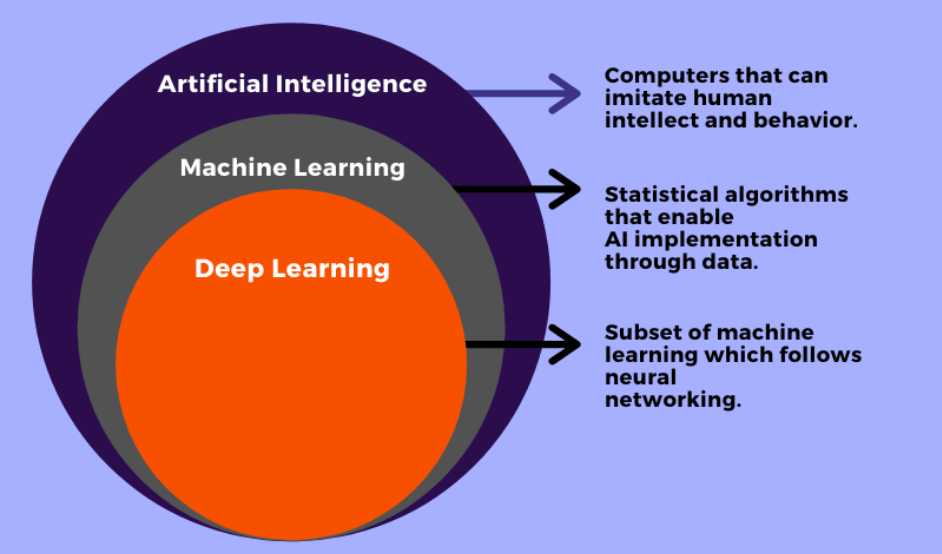
AI is a technique that enables machines to mimic human behavior. Machine learning is a subset of AI technique which uses statistical methods to enable machines to improve with experience. Deep learning is a subset of ML that makes the computation of multi-layer neural networks feasible. It uses neural networks to simulate human-like decision making.
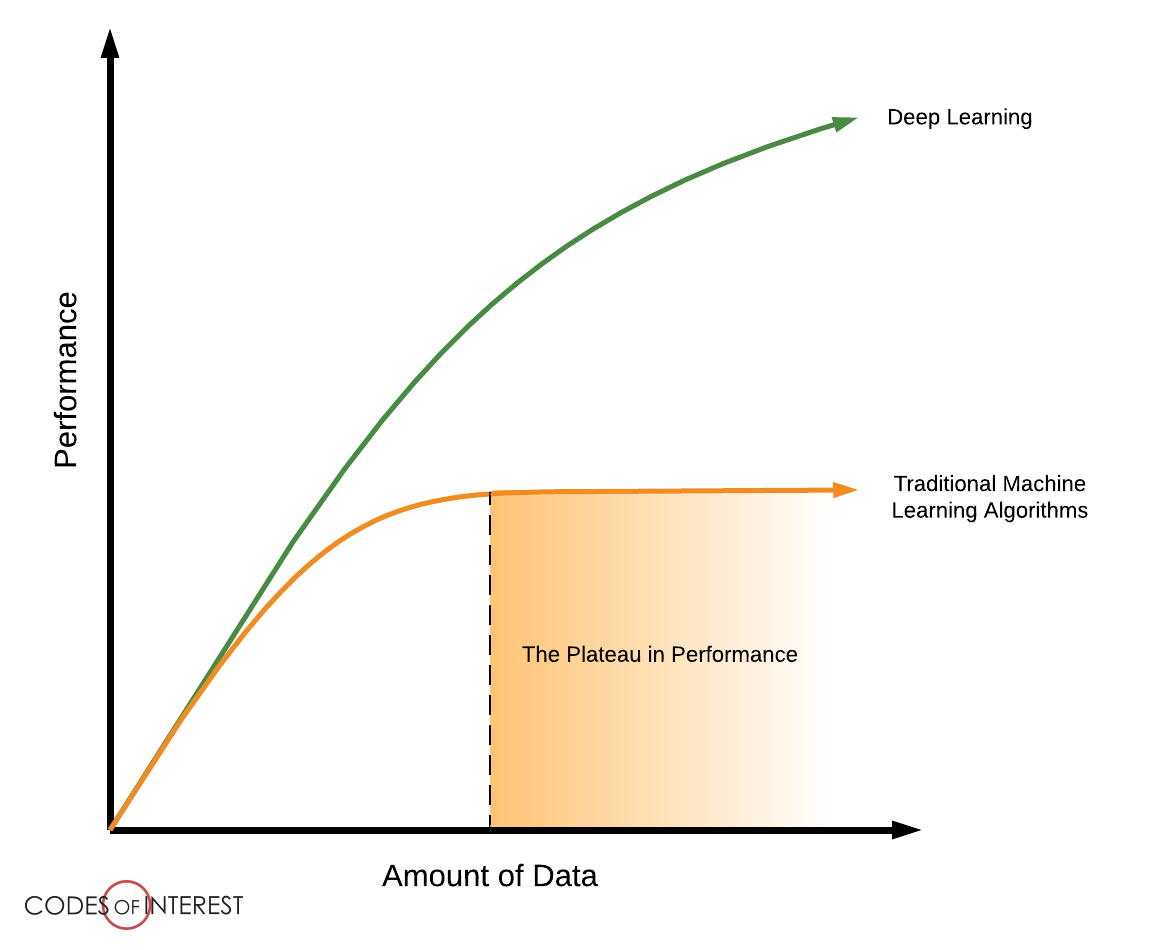
Traditional ML algorithms are not useful when working with high dimensional data involving a large number of inputs and outputs ie. handwriting recognition.
What is a perceptron?

It is a schematic for a neuron. A neuron has:
- Dendrite: receives signals from other neurons (inputs)
- Cell Body: sums all the inputs
- Axon: transmits signals to other cells (output)
A perceptron also receives multiple inputs, applies various transformations and functions to them, and provides an output. This is a linear model used for binary classification.
What are weights, bias, and activation functions?

Each input can be given a specific weight, but there can be one more input called bias. Weights determine the slope of the classifier line, while bias allows us the shift the line towards the left or the right.
The activation function is what translate the inputs into outputs. It decides whether a neuron should be activated or not by calculating the weighted sum and further adding bias with it. The overall purpose of the activation function is to introduce non-linearity to the output of a neuron.
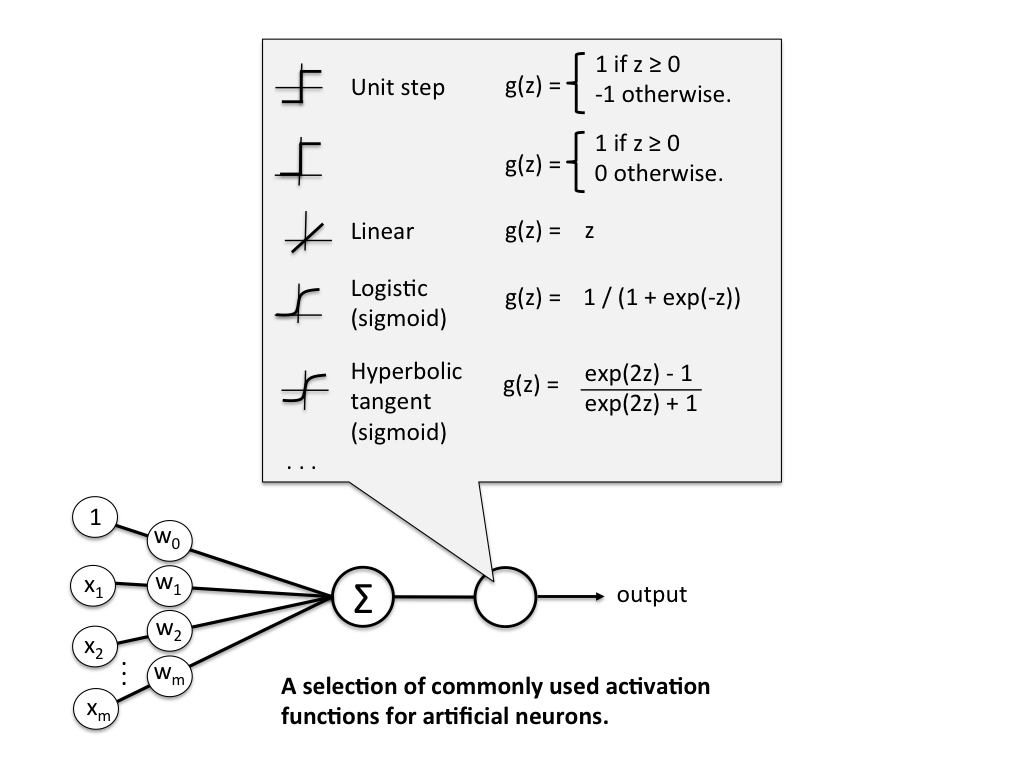
Some examples of activation functions:
- Linear or Identity
- Unit or Binary Step
- Sigmoid or Logistic
- Tanh
- ReLU
- Softmax
How does a perceptron learn?
- Initialize the weights and threshold
- Provide the input and calculate the output
- Update the weights
- Repeat #2 and #3
Wj(t+1) = Wj(t) + n (d-y) x
Wj(t+1) : updated weight Wj(t) : old weight d : desired output y : actual output x : input
What is a cost function / gradient descent?
It’s a measure of accuracy of the neural network with respect to a given training sample and expected output. It can be thought of as a value that represents the performance of the NN as a whole. The goal of Deep Learning is the minimize the cost function by using gradient descent.

This is an optimization algorithm used to minimize some function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient.
- Stochastic Gradient Descent : Uses only a single training example to calculate the gradient and update parameters.
- Batch Gradient Descent : Calculates the gradietns for the whole dataset and performs just one update at each iteration.
- Mini-Batch Gradient Descent : A variation of stochastic gradient descent but instead of using a single training example, a mini-batch of samples is used. It’s the most popular.

As you can see, the mini-batch gradient descent algorithm generalizes finding the flat minima rather than focusing on local minima. As a result, it is more efficient.
Steps for using gradient descent
- Initialize random weight and bias
- Pass an input through the network and get values from the output layer
- Calculate the error between the actual value and the predicted value
- Go to each neuron which contributes the error and then change its respective values to reduce the error.
- Reiterate until you find the best weights of the network.
{
params = [weights_hidden, weights_output, bias_hidden, bias_output]
def sgd(cost, params, lr=0.05)
grads = T.grad(cost=cost, wrt=params)
updates = []
for p, g in zip(params, grads):
updates.append([p, p-q * lr])
return updates
updates = sgd(cost, params)
}